Knowledge Hub
Alles was du über Apache Kafka und die Dataflow Academy wissen musst.


Warum Apache Kafka?
Jedes Unternehmen, das unzählige Datenströme verarbeitet, kann diese mithilfe von Apache Kafka optimieren. Die erste Lektion dieser vierteiligen Blog-Reihe zeigt dir, warum sich größere Organisationen dieser Software zuwenden sollten.
Mehr lesenApache Kafka
Alexander Kropp, Anatoly ZeleninVon den Grundlagen bis zum Produktiveinsatz
Mehr Infos
DataFlow Academy Newsletter
Erhalte unsere neuesten Artikel, Tipps und Tricks direkt in dein E-Mail-Postfach.

Kafka Transaktionen und Exactly-Once-Semantik
Wie du mit Idempotenz, Transaktionen und read_committed in Apache Kafka eine robuste Exactly-Once-Verarbeitung aufbaust.
Mehr lesen
Kroxylicious im Einsatz: Datenvalidierung und End-to-End-Verschlüsselung für Apache Kafka
Garbage In, Garbage Out ist in Kafka ein echtes Problem. Konsumenten stürzen ab, wenn Producer Müll senden. Und wie steht es um die Datensicherheit in der Cloud? In diesem Artikel zeige ich dir, wie du mit dem Kafka-Proxy Kroxylicious deine Daten validierst und verschlüsselst – ohne deinen Anwendungscode anfassen zu müssen.
Mehr lesen
Der Senior-Dev-Faktor: Wie man Kafka-Projekte rettet
Wenn ein Kafka-Projekt stockt, liegt es selten nur an der Technologie. Hartmut Armbruster erklärt, wie er Teams die Angst vor der Infrastruktur nimmt, warum Hackathons ein super Mittel gegen Wissenslücken sind und wie man DuckDB für das ultimative Kafka-Debugging nutzt.
Mehr lesen
Der Forever-Log: Warum Tiered Storage die Rechnung (und die Risiken) verändert
Tiered Storage verwandelt Kafka in ein System of Record mit unbegrenzter Retention. Doch mit großen Möglichkeiten kommen neue Albträume. Anatoly Zelenin und Bryan De Smaele diskutieren, warum Replikation kein Backup ist und warum ein einziges gelöschtes Topic Terabytes an Daten vernichten kann.
Mehr lesen
Kafka Sizing & Scaling: Hardware-Anforderungen und Strategien zur Skalierung
Man braucht kein riesiges Cluster, um Kafka produktiv zu betreiben. Wir räumen mit Hardware-Mythen auf und zeigen, wie man mit 3 Brokern effizient startet und sauber skaliert.
Mehr lesen
Plattform-Engineering, Cloud-Kosten und das "Copy-Paste-Problem": Alex Kropp im Interview
Alexander Kropp, Plattform-Ingenieur bei der DataFlow Academy, spricht im Interview über Cloud-Kosten, das "Copy-Paste-Problem" bei Tech-Stacks und warum Plattform-Teams die wichtigsten Tech-Multiplikatoren im Unternehmen sind.
Mehr lesen
Vom Datensilo zum Flow-Ökosystem: Das 5-Stufen-Reifegradmodell für Unternehmen
Erfahre, wie Unternehmen mit Apache Kafka ihre veralteten Datenarchitekturen modernisieren. Dieses 5-Stufen-Modell zeigt dir den Weg vom isolierten Datensilo zum agilen Echtzeit-Ökosystem und hilft dir, die Position deines Unternehmens einzuordnen.
Mehr lesen
Apache Kafka Clients richtig konfigurieren
Die Standardkonfigurationen von Kafka reichen für die Entwicklung, aber in der Produktion sind sie eine Schwachstelle. Dieser Leitfaden deckt die wesentlichen Einstellungen für Zuverlässigkeit, Performance und Betriebsstabilität ab.
Mehr lesen
Beyond Bytes: Die vier Nachrichtentypen in Kafka verstehen
Kafkas Flexibilität ist ein zweischneidiges Schwert. Dieser Leitfaden stellt die vier primären Nachrichtentypen vor: States, Deltas, Events und Commands. Er zeigt Ihnen, wie Ihr Eure Datenströme zielgerichtet gestalten könnt, was zu robusten und skalierbaren Architekturen führt.
Mehr lesen
Apache Kafka im Überblick
Unternehmen nutzen Apache Kafka, um Entscheidungen nahezu in Echtzeit zu treffen. Diese Datendrehscheibe und Event-Streaming-Plattform ermöglicht Antworten in dem Moment, in dem die Fragen aufkommen, und hilft Organisationen dabei, vom Warten zum Handeln zu kommen.
Mehr lesen
Wie REWE mit Apache Kafka die digitale Transformation meistert
Ob beim Online-Einkauf, beim Self-Checkout im Markt oder bei der Belieferung nach Hause: Fast jeder Deutsche hat regelmäßig mit REWE zu tun. Was die wenigsten wissen: Hinter den Kulissen sorgt Apache Kafka dafür, dass alles reibungslos läuft. Paul Puschmann und Patrick Wegner geben Einblicke in die technologische Transformation eines der größten deutschen Einzelhändler.
Mehr lesen
Kafka: Wie du Datenverlust beim Produzieren garantiert vermeidest
Du willst sicherstellen, dass keine einzige Kafka-Nachricht verloren geht? In diesem Guide zeige ich dir, wie du mit den richtigen Konfigurationen eine maximale Zuverlässigkeit beim Produzieren erreichst und was du im Fehlerfall tun musst.
Mehr lesen
Das Beste an Apache Kafka? Es ist langweilig!
Wie ein System, das einfach funktioniert, der deutschen Medienlandschaft hilft, täglich Millionen Leser zu zählen. Ein Interview mit Felix Sponholz.
Mehr lesen
Strimzi installieren
In diesem Beitrag erfährst du, wie du Strimzi auf einem K3s-Cluster installieren kannst.
Mehr lesen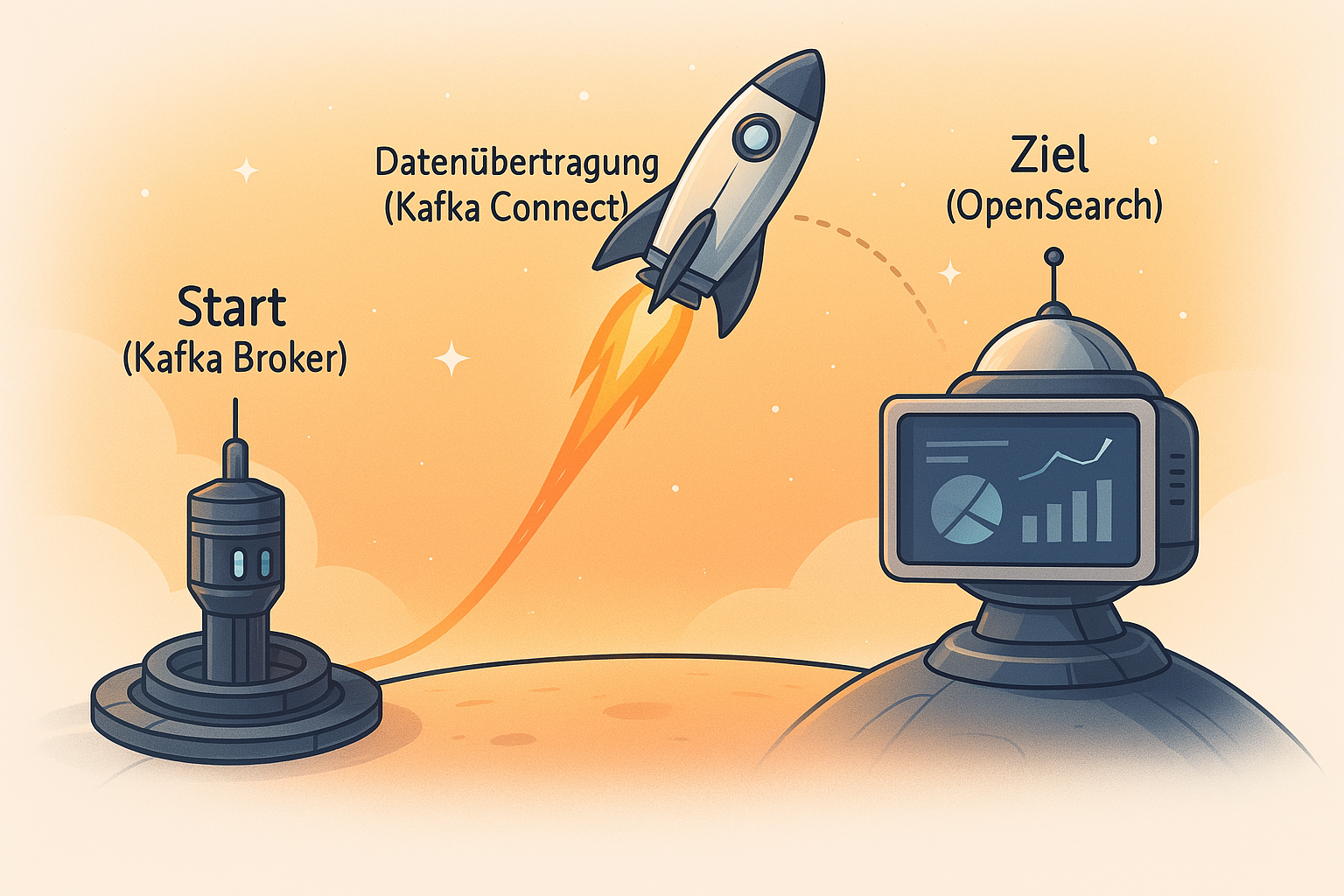
Praxisguide: Streame Daten von Kafka nach OpenSearch in Kubernetes
In diesem Artikel zeige ich, wie du Daten aus einem Kafka Topic automatisch nach OpenSearch senden kannst. Wir nutzen dafür Kafka Connect und Strimzi in Kubernetes.
Mehr lesen
Kafka im Automotive: Die Lösung für den exponentiell wachsenden Datenverkehr?
Moderne Fahrzeuge produzieren Unmengen an Daten. Damit fordern sie nicht nur Mobilfunknetze, sondern auch die IT-Systeme der Hersteller heraus. Wie kann Apache Kafka dabei helfen?
Mehr lesen
Schema Management in Kafka
In diesem Post erfährst du, wie explizite Schemas, dir dabei helfen, ein mögliches Chaos in Kafka zu vermeiden und wie die Schema Registries dabei unterstützen.
Mehr lesen
Debezium: Change Data Capture für Apache Kafka
In diesem Post zeigen wir euch, wie ihr mithilfe von Debezium Daten aus verschiedenen Datenbanken zuverlässig und nahezu in Echtzeit nach Kafka importieren könnt. Debezium ist ein Kafka Connect-Plugin, das sich an das interne Log jeder Datenbank anschließen kann, um Änderungen zu erfassen und in Kafka zu schreiben.
Mehr lesen
Kafka-Testumgebung einrichten
Lerne, wie wir eine Multi-Node Kafka-Testumgebung auf einem einzelnen Rechner für Entwicklungs- und Testzwecke einrichten. Diese Anleitung zeigt uns, wie wir drei Kafka-Broker mit korrekter Controller-Konfiguration konfigurieren.
Mehr lesen
Kafka in Banken: Eine Verbindung zwischen den Welten – für langfristig wirtschaftliche Projekte
Kernbankensysteme kümmern sich um die wichtigsten Prozesse im Bankenwesen. Das Problem: Diese unbeweglichen Kolosse harmonieren nur selten mit den Wünschen der heutigen Kundinnen und Kunden. Es braucht Systeme, die das Alte mit dem Neuen verbinden. In vielen Bankhäusern wird dafür auf Apache Kafka gesetzt. Warum?
Mehr lesen
Logistik: Wie die Branche mit Kafka wachsenden Belastungen trotzen kann
Wachsende Paketmengen. Poröse Lieferketten. Logistikfirmen stehen vor großen Problemen. Sie müssen mehr denn je in Echtzeit die richtigen Entscheidungen treffen. Das gelingt jedoch nicht ohne Echtzeitdaten. Wie Apache Kafka und dessen Ökosystem Unternehmen dabei helfen.
Mehr lesen
Kafka Training: Die 6 wichtigsten Leitprinzipien meiner Trainings
Wann bin ich ein guter Trainer? Das ist für mich vielleicht die wichtigste Frage in meiner Rolle als Apache-Kafka-Experte. In diesem Blog will ich sie mit sechs Leitprinzipien beantworten. Stimmst du mir bei allen zu?
Mehr lesen
Daten als Produkt: die 6 Prinzipien des effektiven Datenmanagements
Daten liegen in Echtzeit vor. Die Infrastruktur für Microservices steht. Das Ziel ist klar: Wir wollen nun das Data Mesh. Doch wie erreichen wir damit unsere Fachbereiche? Warum das Datenmanagement eine Kultur- und Produktfrage ist.
Mehr lesen
Ausblick auf das Data Mesh: 4 Schritte für den Paradigmenwechsel
Das „Data Mesh“ ist in der IT-Szene ein echter Hype. Warum Unternehmen von einer dezentralisierten Datenarchitektur profitieren und wie Apache Kafka beim Etablieren dieser neuen Struktur hilft, erörtert dieser Artikel.
Mehr lesen
Daten in einer Microservice-Welt
Von Start-up bis Konzern – immer mehr Unternehmen setzen auf Microservice-Architekturen. In der zweiten Lektion der vierteiligen Blogreihe erfährst du, wie Unternehmen mithilfe von Apache Kafka die Kommunikation zwischen ihren Services vereinfachen.
Mehr lesen
Warum Apache Kafka?
Jedes Unternehmen, das unzählige Datenströme verarbeitet, kann diese mithilfe von Apache Kafka optimieren. Die erste Lektion dieser vierteiligen Blog-Reihe zeigt dir, warum sich größere Organisationen dieser Software zuwenden sollten.
Mehr lesen
Apache Kafka – Von den Grundlagen bis zum Produktiveinsatz
Apache Kafka – Von den Grundlagen bis zum Produktiveinsatz begleitet dich durch die Konzepte und Fertigkeiten, die du benötigst, um Kafka für Datenpipelines, Event-getriebene Anwendungen und andere Systeme einzusetzen und zu administrieren, die Datenströme aus mehreren Quellen verarbeiten.
Mehr lesen
Erste Schritte mit Apache Kafka
Bevor wir uns in all die Details stürzen, lass uns gemeinsam unsere Apache Kafka Rakete starten und einen Blick darauf werfen, wie sie sich in einem ersten Testflug bewährt. Jede Raketenwissenschaft muss schließlich irgendwann einmal beginnen. In diesem Sinne: 3, 2, 1 … Zündung
Mehr lesen
Was ist Apache Kafka?
Was hat es eigentlich überhaupt mit Apache Kafka auf sich? Diesem Programm, das quasi jeder namhafte (deutsche) Automobilhersteller einsetzt? Diese Software, dank derer wir mit unseren Schulungen und Workshops kreuz und quer durch Europa gereist sind und viele unterschiedliche Branchen ‒ von Banken, Versicherungen, Logistik-Dienstleistern, Internet-Start-ups, Einzelhandelsketten bis hin zu Strafverfolgungsbehörden ‒ kennengelernt haben? Warum setzen so viele unterschiedliche Unternehmen Apache Kafka ein?
Mehr lesen
Wie viele Partitionen brauche ich in Apache Kafka?
Die Partitionen in Apache Kafka sind wesentlich für die Aufrechterhaltung von Ordnung und Struktur in allen Datenverarbeitungsabläufen. Doch wie viele Partitionen sollte man einrichten? Eine wichtige Frage, die frühzeitig in der Systemplanung berücksichtigt werden sollte. Dieser Blog-Beitrag behandelt diese kritische Überlegung für eure Kafka-Implementierung.
Mehr lesenWir glauben an eine Welt, in der Unternehmen durch Echtzeitdaten intelligenter entscheiden, nachhaltiger handeln und ihre digitale Zukunft aktiv gestalten.
Copyright 2026, Alle Rechte vorbehalten
Kontakt
Adresse
Commit to Flow GmbH
Wiener Platz 11
01069 Dresden