Logistik: Wie die Branche mit Kafka wachsenden Belastungen trotzen kann

Von Anatoly Zelenin
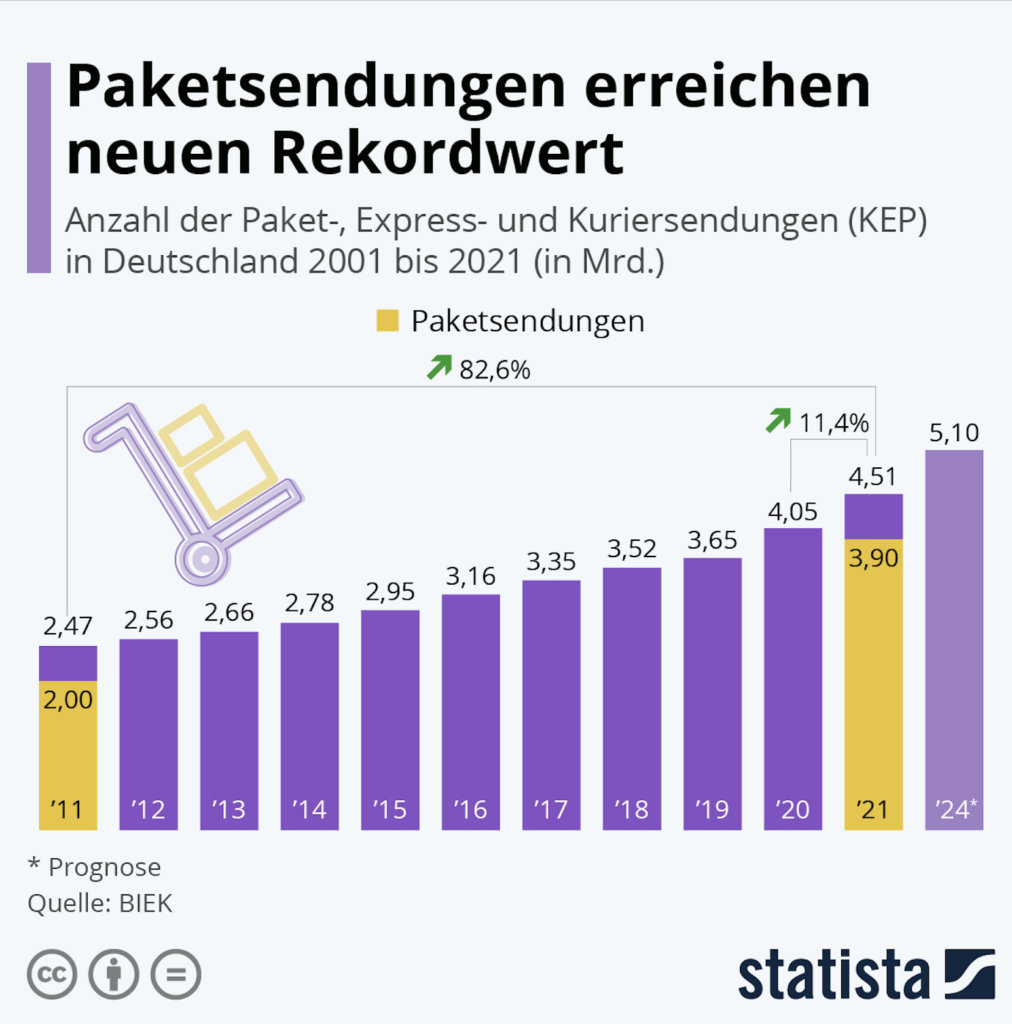
Im Jahr 2010 wurden in Deutschland 2 Milliarden Pakete verschickt. 2021 waren es – auch beschleunigt durch Corona – 4,51 Milliarden. Schon 2024 sollen es bereits mehr als 5 Milliarden sein. Tendenz steigend. Auch erkennbar an aussterbenden Händlern in den Innenstädten.
Doch es ist nicht nur die schiere Menge, die Logistikunternehmen herausfordert. Die Ansprüche von Behörden und Endverbrauchenden wachsen ebenfalls. Die Kernbedürfnisse: Transparenz und eine höhere Liefergeschwindigkeit.
Wer sich mit der Branche beschäftigt, wird verstehen, dass das Geschwätz um Lieferdrohnen tatsächlich genau das noch eine Weile bleiben wird: Zukunftsgeschwätz. Logistiker müssen vor den Träumen erst mal jede Menge Hausaufgaben erfüllen.
Was bedeutet das?
Kundinnen und Kunden wollen ihre Pakete live verfolgen. Das ist nicht neu, aber die Intensität verändert sich. Früher genügten Updates im Stundentakt. Nun müssen Unternehmen jederzeit transparent darstellen können, wo sich Pakete befinden und wann sie bei den Empfänger:innen ankommen – und zwar auf die Viertelstunde genau.
Bei internationalen Warenlieferungen wollen Zollbehörden noch früher über Sendungen informiert werden. Es geht um mehr als eine elektronische Vorankündigung. Der Zoll will künftig noch mehr Daten erhalten.
Noch dazu verändert sich das Geschäft mit großen Versandhändlern. Diese wollen aus Kostengründen weite Etappen der Logistik selbst übernehmen. Das heißt: Erst während der letzten Meile auf die etablierten Dienste zurückgreifen. Das macht ein ohnehin schwer planbares Geschäft noch schwieriger zu antizipieren. Immerhin kann jeder Stau oder Schienenschaden Unternehmen aus der Fasson bringen.
Von neuen Herausforderungen zu sprechen, wäre aber nicht korrekt. Analytisch betrachtet handelt es sich eher um eine Verschärfung – oder, dramatischer, eine Eskalation. Das Problem ist Folgendes:
Auch wenn Lieferdienste sich in der IT angestrengt haben, konnte das Wachstum der Datenstrukturen nicht mit dem des Geschäftsvolumens mithalten. Daraus ergibt sich eine komplexe Aufgabe.
Zusammengefasst
Wie lassen sich die zentralen Datenautobahnen im laufenden Geschäft umbauen – und das ohne Verkehrsbehinderungen im Tagesgeschäft?
Die erwarteten Datenmengen werden massiv wachsen. Manche Logistikunternehmen erwarten mehr als hundertfache Steigerungen. Wie könnten Systeme diese Last tragen?
Dazu müssen Daten schneller verfügbar sein – und zwar am besten in Echtzeit, auf die Sekunde genau.
Mit Apache Kafka lassen sich diese Herausforderungen tatsächlich lösen. Als Experte und Trainer habe ich dabei folgende Erwartungen:
Nicht nur die Menge der Daten wird signifikant steigen. Gleiches gilt für die Anzahl der involvierten externen Systeme. Auf ihren Datenautobahnen müssen Firmen nicht nur mehr Datenlast transportieren. Auch Schnittstellen – analog zu Ab- und Auffahrten – müssen rasch integriert werden.
Obwohl mehr Datenverkehr herrscht, muss dieser noch flüssiger als zuvor laufen. Nur dann stehen Informationen in Echtzeit bereit.
Datenschutz bleibt in diesem Zusammenhang wichtig. Viele Beteiligte dürfen nur ganz individuelle Daten erhalten und einsehen. Informationen müssen jeweils individuell verpackt und verschickt werden. Und das muss so rasch funktionieren, dass das Echtzeit-Versprechen erfüllt werden kann.
Nicht nur das Management will Analysen erhalten, sondern auch Logistikzentren. Diese benötigen diese jedoch noch schneller. Sie müssen wissen, welches Paketaufkommen sie in den kommenden Minuten, Stunden oder Tagen disponieren müssen.
In vielen Konzernen fungiert Apache Kafka als zentrale Plattform für den Datenaustausch. Manche Unternehmen bezeichnen Kafka sogar als „Paket-Daten-Betriebssystem“.
Und so hilft Kafka konkret Logistikunternehmen:
Mit Kafka lassen sich im Vergleich zu bisherigen Systemen deutlich höhere Datenmengen skalieren. Auch wenn sich die Datenmengen vervielfachen, wird Kafka nicht zum Flaschenhals im System.
Mithilfe von Kafka können Unternehmen Daten nahezu in Echtzeit an viele unterschiedliche Systeme weiterleiten. So können diverse Teams unabhängig auf dieselben Daten zugreifen. Das Motto: Daten zentralisieren – Datenzugriffe demokratisieren. Das natürlich nur innerhalb des Unternehmens mit den vorgegebenen Berechtigungen.
Kafka ermöglicht beim Thema Datenzugriff agilere Methoden. Bei manchen Kunden reduziert sich die Zeit von Antrag auf Zugang bis zur Implementierung von 4–5 Wochen auf 1–2 Tage.
Kafka ist erstaunlich robust. Nach der initialen Implementierung läuft Kafka oft „einfach“ – von allein. Nur bei sehr großen Datenmengen sind weitere Maßnahmen notwendig.
Zur Wahrheit gehört an dieser Stelle:
Kafka allein genügt nicht – es ist nur der Kern. Ein Begriff, der mir besser gefällt: die Datendrehscheibe. Ist Kafka einmal installiert und können Menschen mit diesem Werkzeug umgehen, gibt es im Ökosystem zahlreiche ergänzende Lösungen.
So empfinden nicht nur Privathaushalte den Paketversand als stressfreier und bequemer, sondern auch die Logistikunternehmen selbst.
Demnächst wird dieser Blog um ein Case-Interview aus der Branche erweitert.
Über Anatoly Zelenin
Hallo, ich bin Anatoly! Ich liebe es, bei Menschen das Funkeln in den Augen zu wecken. Als Apache Kafka Experte und Buchautor bringe ich seit über einem Jahrzehnt IT zum Leben - mit Leidenschaft statt Langeweile, mit Erlebnissen statt endlosen Folien.
Weiterlesen

Kafka im Automotive: Die Lösung für den exponentiell wachsenden Datenverkehr?
Moderne Fahrzeuge produzieren Unmengen an Daten. Damit fordern sie nicht nur Mobilfunknetze, sondern auch die IT-Systeme der Hersteller heraus. Wie kann Apache Kafka dabei helfen?
Mehr lesen
Kafka in Banken: Eine Verbindung zwischen den Welten – für langfristig wirtschaftliche Projekte
Kernbankensysteme kümmern sich um die wichtigsten Prozesse im Bankenwesen. Das Problem: Diese unbeweglichen Kolosse harmonieren nur selten mit den Wünschen der heutigen Kundinnen und Kunden. Es braucht Systeme, die das Alte mit dem Neuen verbinden. In vielen Bankhäusern wird dafür auf Apache Kafka gesetzt. Warum?
Mehr lesenWir glauben an eine Welt, in der Unternehmen durch Echtzeitdaten intelligenter entscheiden, nachhaltiger handeln und ihre digitale Zukunft aktiv gestalten.
Copyright 2026, Alle Rechte vorbehalten
Kontakt
Adresse
Commit to Flow GmbH
Wiener Platz 11
01069 Dresden