Logistics: How the Industry Can Withstand Growing Pressures with Kafka
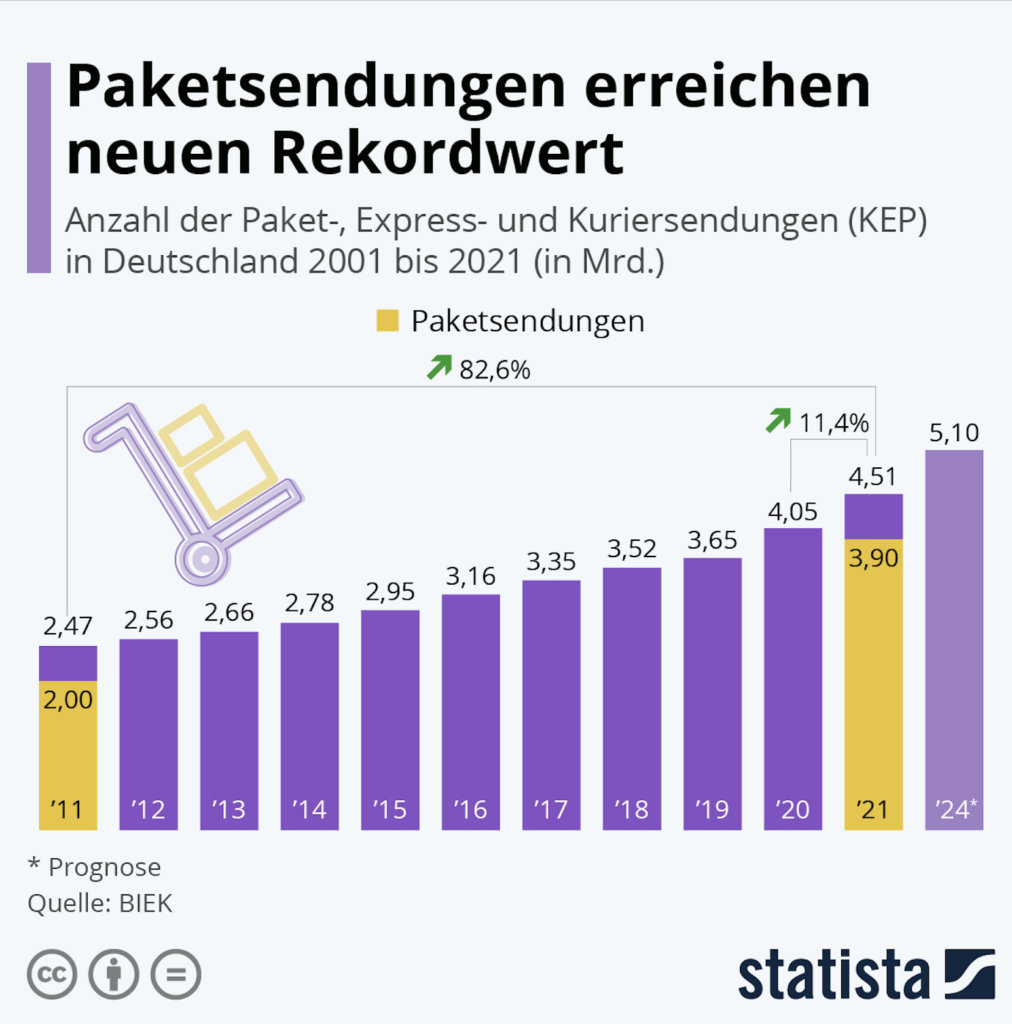
In 2010, 2 billion packages were shipped in Germany. In 2021 – accelerated by the pandemic – this number reached 4.51 billion. By 2024, it’s expected to exceed 5 billion. The trend is upward, also evident in the disappearance of retailers from city centers.
But it’s not just the sheer volume that challenges logistics companies. The demands from authorities and end consumers are also growing. The core needs: transparency and faster delivery speeds.
Those familiar with the industry will understand that all the talk about delivery drones will remain just that for a while yet: future talk. Before these dreams, logistics companies have plenty of homework to complete.
What does this mean?
Customers want to track their packages live. This isn’t new, but the intensity is changing. Previously, hourly updates were sufficient. Now, companies must be able to transparently show where packages are and when they will arrive at their recipients – accurate to the quarter hour.
For international shipments, customs authorities want to be informed about shipments even sooner. It’s about more than just electronic pre-notification. In the future, customs will want to receive even more data.
Additionally, the business with large online retailers is changing. For cost reasons, these companies want to handle large segments of logistics themselves. This means: only relying on established services for the last mile. This makes an already difficult-to-plan business even harder to anticipate. After all, any traffic jam or rail damage can throw companies off course.
However, it would be incorrect to speak of new challenges. Analytically speaking, it’s more of an intensification—or, more dramatically, an escalation. The problem is as follows:
Even though delivery services have made efforts in IT, the growth of data structures has not kept pace with business volume. This creates a complex task.
In summary
How can the central data highways be restructured during ongoing operations – and without disrupting daily business?
The expected data volumes will grow massively. Some logistics companies expect more than a hundredfold increase. How could systems handle this load?
Additionally, data needs to be available faster – ideally in real-time, to the second.
With Apache Kafka, these challenges can actually be solved. As an expert and trainer, I have the following expectations:
Not only will the amount of data increase significantly. The same applies to the number of external systems involved. On their data highways, companies must not only transport more data load. Interfaces—analogous to on- and off-ramps—must also be quickly integrated.
Although there is more data traffic, it must flow even more smoothly than before. Only then will information be available in real-time.
Data protection remains important in this context. Many participants may only receive and view very specific data. Information must be individually packaged before sending. And this must happen quickly enough to fulfill the real-time promise.
Not only does management want to receive analyses, but logistics centers do as well. However, they need it even faster. They need to know what package load they must manage in the coming minutes, hours, or days.
In many corporations, Apache Kafka serves as the central platform for data exchange. Some companies even refer to Kafka as a “package data operating system.”
And this is how Kafka concretely helps logistics companies:
Kafka can scale to handle significantly higher data volumes compared to previous systems. Even when data volumes multiply, Kafka doesn’t become a bottleneck in the system.
With Kafka, companies can route data to many different systems in near real-time. This allows various teams to independently access the same data. The motto: centralize data – democratize data access. Of course, this is only within the company with the predetermined permissions.
Kafka enables more agile methods when it comes to data access. For some customers, the time from access request to implementation is reduced from 4–5 weeks to 1–2 days.
Kafka is surprisingly robust. After the initial implementation, Kafka often “just” runs—on its own. Only with very large data volumes are additional measures necessary.
The truth at this point:
Kafka alone is not enough—it is only the core. A term I prefer: the data hub. Once Kafka is installed and people can operate this tool, there are numerous complementary solutions in the ecosystem.
As a result, not only will private households find package shipping less stressful and more convenient, but so will the logistics companies themselves.
Soon, this blog will be expanded with a case interview from the industry.

About Anatoly Zelenin
Hi, I’m Anatoly! I love to spark that twinkle in people’s eyes. As an Apache Kafka expert and book author, I’ve been bringing IT to life for over a decade—with passion instead of boredom, with real experiences instead of endless slides.
Continue reading

Kafka in Automotive: The Solution for Exponentially Growing Data Traffic?
Modern vehicles produce enormous amounts of data. This challenges not only mobile networks but also the IT systems of manufacturers. How can Apache Kafka help?
Read more
Kafka in Banking: A Bridge Between Worlds – for Long-term Economical Projects
Core banking systems handle the most important processes in banking. The problem: These inflexible giants rarely harmonize with the wishes of today's customers. Systems are needed that connect the old with the new. Many banks rely on Apache Kafka for this. Why?
Read moreWe believe in a world where companies make better decisions with real-time data, act sustainably, and actively shape their digital future.
Copyright 2026, All Right Reserved
Contact
Address
Commit to Flow GmbH
Wiener Platz 11
01069 Dresden